
- August 10, 2023
- Posted by: team SOUTECH
- Category: Blog, Data Analysis and Virtualization, Data Science Free Training, Others, Technologies
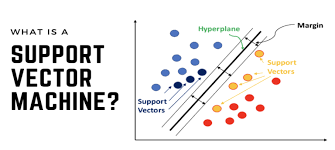
Introduction: Support Vector Machines (SVM) is a popular and versatile supervised learning algorithm used for both classification and regression tasks. SVM has gained widespread attention due to its ability to handle high-dimensional data, non-linear relationships, and robustness against overfitting. In this article, we will delve into the concepts of SVM, understand its underlying principles, and explore its applications in real-world scenarios.
Section 1: Understanding the Basics of Support Vector Machines
– Intuition behind SVM: Explaining the geometric intuition behind SVM’s classification approach.
– Hyperplanes and Margins: Understanding how SVM identifies optimal hyperplanes that best separate classes with the maximum margin.
– Linear vs. Non-linear SVM: Discussing the kernel trick and how SVM can handle non-linearly separable data.
Section 2: The Mathematics Behind SVM
– Formulation of the optimization problem: Explaining the mathematical formulation of SVM as a convex optimization problem.
– Lagrange multipliers: Introducing Lagrange multipliers to solve the constrained optimization problem efficiently.
– Kernel functions: Understanding different kernel functions like linear, polynomial, radial basis function (RBF), and their role in mapping data into higher-dimensional space.
Section 3: SVM for Classification and Regression
– Binary classification: Applying SVM to separate data into two classes with the help of decision boundaries.
– Multi-class classification: Extending SVM for multi-class classification using techniques like One-vs-Rest and One-vs-One.
– Support Vector Regression: Using SVM for regression tasks to predict continuous values.
Section 4: Real-world Applications and Case Studies
– Image recognition: Utilizing SVM for image classification tasks like handwritten digit recognition.
– Bioinformatics: Applying SVM in gene expression analysis and protein classification.
– Finance: Using SVM for credit risk assessment and stock market prediction.
Section 5: Model Selection and Hyperparameter Tuning
– Selecting the right kernel: Understanding the impact of kernel selection on SVM’s performance.
– C parameter: Exploring the role of the regularization parameter C and its influence on the trade-off between bias and variance.
– Cross-validation: Employing cross-validation techniques for model selection and hyperparameter tuning.
Section 6: Pros and Cons of Support Vector Machines
– Advantages of SVM: Discussing SVM’s strengths, such as handling high-dimensional data and non-linear relationships.
– Limitations of SVM: Addressing SVM’s challenges, such as sensitivity to noise and computational complexity.
Conclusion:Support Vector Machines (SVM) is a powerful and versatile algorithm that continues to find applications across various domains due to its ability to handle complex data and deliver accurate predictions. As we’ve explored in this article, SVM’s geometric intuition, mathematical formulation, and flexibility make it an indispensable tool in the arsenal of data scientists. By mastering SVM’s concepts and techniques, data scientists can leverage its capabilities to solve a wide range of classification and regression problems in real-world scenarios.
Related posts:
 “Game On: Elevating Sports Excellence through Data Science and Analytics”
“Game On: Elevating Sports Excellence through Data Science and Analytics”
 Machine Learning and Artificial Intelligence a Bigger Picture
Machine Learning and Artificial Intelligence a Bigger Picture
 Lexicon Alchemy: Transforming Language into Intelligence with Natural Language Processing (NLP)
Lexicon Alchemy: Transforming Language into Intelligence with Natural Language Processing (NLP)
 How to become an expert in R for data science and machine learning – step by step guide
How to become an expert in R for data science and machine learning – step by step guide
 Ethics Unveiled: Navigating Data Privacy and Responsibility in the Age of Innovation
Ethics Unveiled: Navigating Data Privacy and Responsibility in the Age of Innovation