
- August 14, 2020
- Posted by: Data Science Training and Solution
- Category: Data Analysis and Virtualization, Data Science Free Training

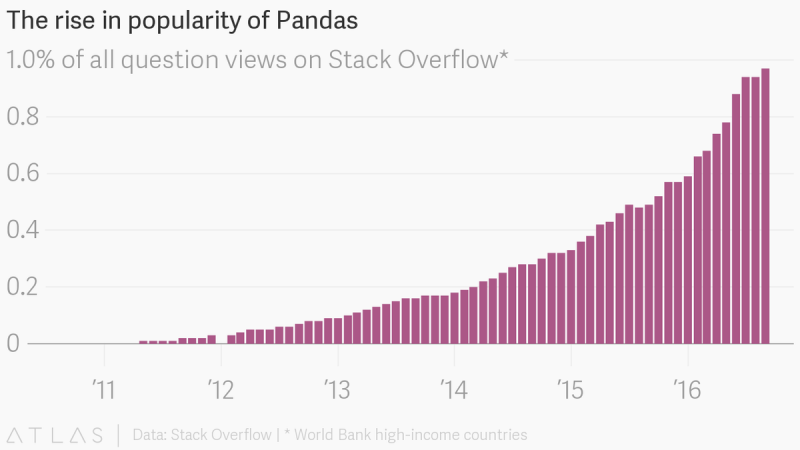
pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
Pandas is built on top of the NumPy package, meaning a lot of the structure of NumPy is used or replicated in Pandas. Data in pandas is often used to feed statistical analysis in SciPy, plotting functions from Matplotlib, and machine learning algorithms in Scikit-learn.
Pandas First Steps
Install and import
Pandas is an easy package to install. Open up your terminal program (for Mac users) or command line (for PC users) and install it using either of the following commands:
conda install pandas
OR
pip install pandas
Alternatively, if you’re currently viewing this article in a Jupyter notebook you can run this cell:
The ! at the beginning runs cells as if they were in a terminal.
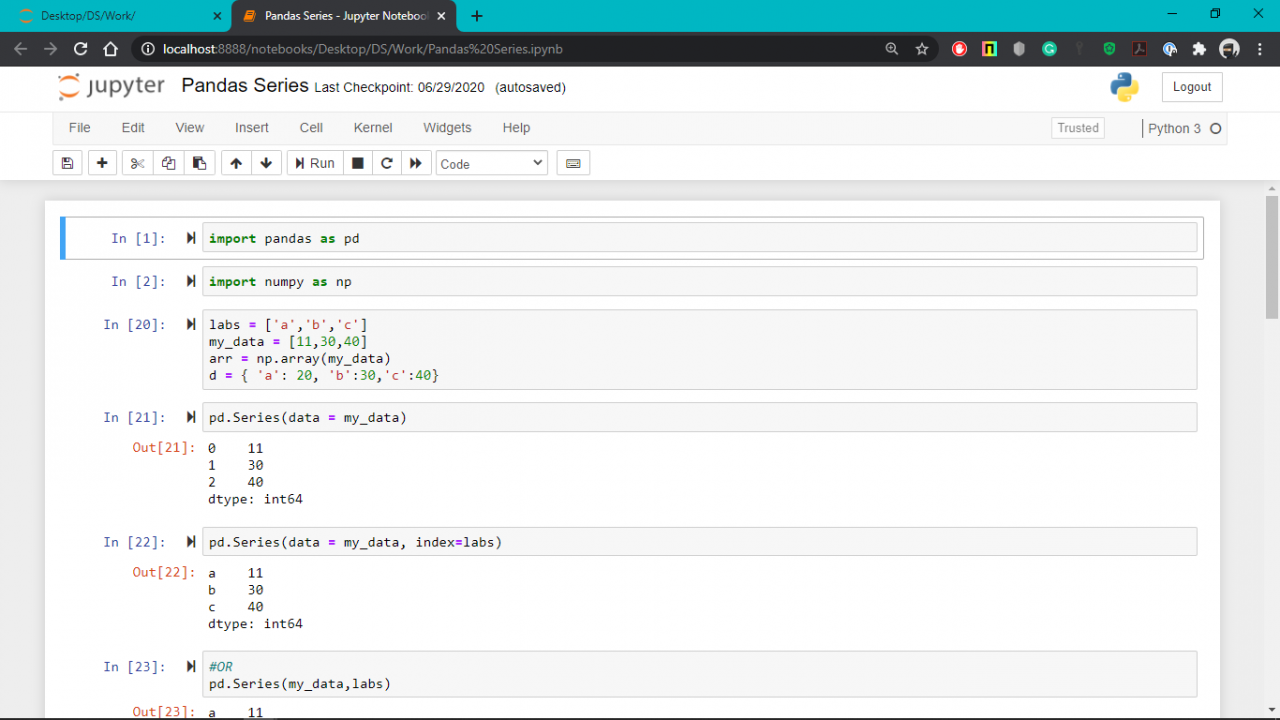
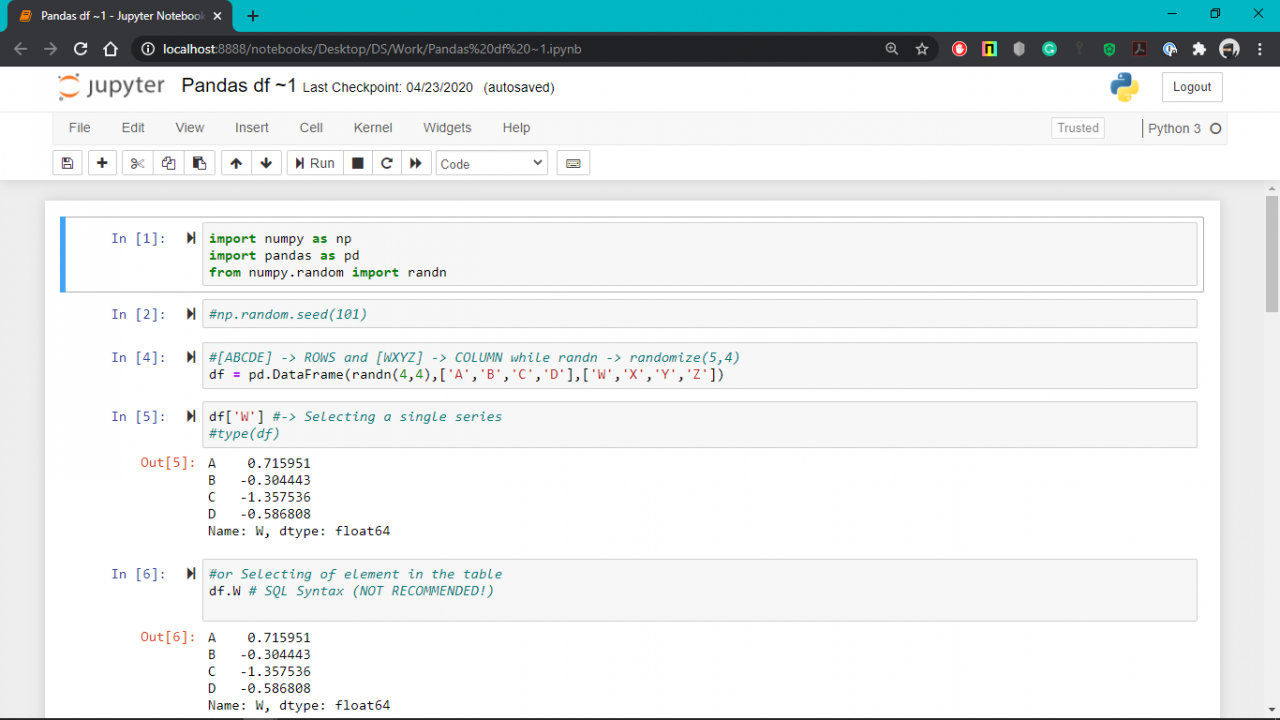
To import pandas we usually import it with a shorter name since it’s used so much:
Related posts:
 Python Data Science Tools: How to Install Jupyter NoteBook Tutorial
Python Data Science Tools: How to Install Jupyter NoteBook Tutorial
 Python for Data Analysis Training in Abuja Lagos PH Nigeria 2023
Python for Data Analysis Training in Abuja Lagos PH Nigeria 2023
 R and R Studio Installation and Set up for Data Analysis Nigeria
R and R Studio Installation and Set up for Data Analysis Nigeria
 Python for Beginners: Learning Python Programming Language Fast
Tutorial on SQL Injection: SOUTECH Ventures
Python for Beginners: Learning Python Programming Language Fast
Tutorial on SQL Injection: SOUTECH Ventures