
- January 10, 2019
- Posted by: SouTech Team
- Category: Blog, Python Development

Python is free, open-source software, and consequently anyone can write a library package to extend its functionality. Data science has been an early beneficiary of these extensions, particularly Pandas, the big daddy of them all.
Pandas is the Python Data Analysis Library, used for everything from importing data from Excel spreadsheets to processing sets for time-series analysis. Pandas puts pretty much every common data munging tool at your fingertips. This means that basic cleanup and some advanced manipulation can be performed with Pandas’ powerful dataframes.
Pandas is built on top of NumPy, one of the earliest libraries behind Python’s data science success story. NumPy’s functions are exposed in Pandas for advanced numeric analysis.
If you need something more specialized, chances are it’s out there:
- SciPy is the scientific equivalent of NumPy, offering tools and techniques for analysis of scientific data.
- Statsmodels focuses on tools for statistical analysis.
- Scilkit-Learn and PyBrain are machine learning libraries that provide modules for building neural networks and data preprocessing.

And these just represent the peoples’ favorites. Other specialized libraries include:
- SymPy – for statistical applications
- Shogun, PyLearn2 and PyMC – for machine learning
- Bokeh, d3py, ggplot, matplotlib, Plotly, prettyplotlib, and seaborn – for plotting and visualization
- csvkit, PyTables, SQLite3 – for storage and data formatting
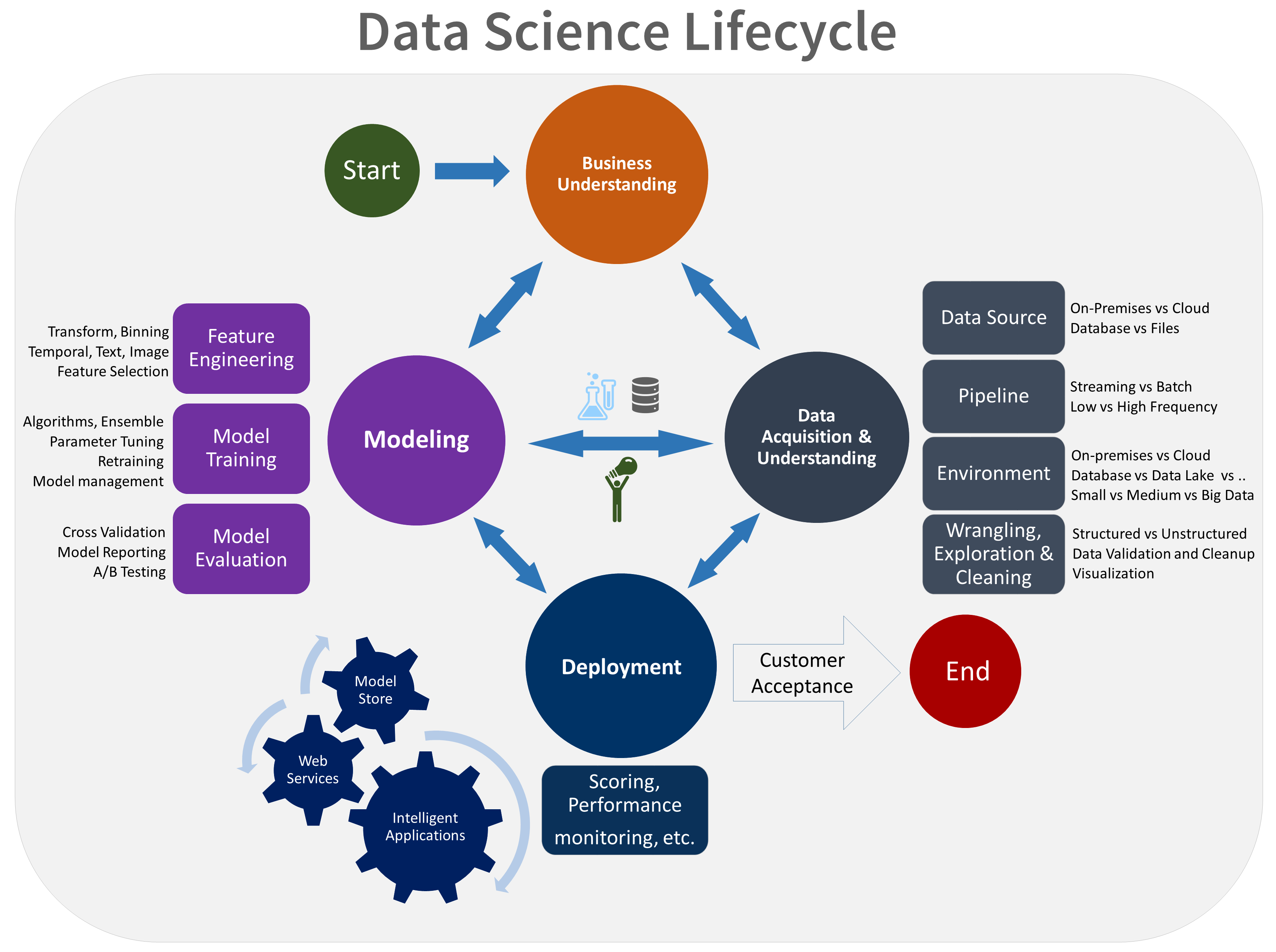
The data science process is broken down into a series of stages:
- Acquire: Obtain the data
- Prepare: Manipulate the data to fit analytic needs
- Analyze: Explore the data
- Act: Turn the data into actions
Within the data science process, a number of sub-steps exist, which include:
- Defining the business outcome and ensuring the modeling output is practical and actionable from a business perspective
- Assessing the currently available data and the volume of data required to develop the model (data mining)
- Selecting the appropriate development tools or technologies depending on the volume, velocity, and variety of data
- Acquiring data and identifying sources
- Identifying and remediating data quality issues
Once the data science process has been satisfied, data scientists may choose to:
- Publish or share the results with colleagues for peer review
- Embed the model into a report or dashboard within the organization to make business decisions
- Deploy the model into production
Here are some Applications/Uses of Data Science:-
~ Internet Search
~ Digital Advertisements (Targeted Advertising and re-targeting)
~ Recommender Systems
~ Image Recognition
~ Speech Recognition
~ Gaming
~ Price Comparison Websites
~ Airline Route Planning
~ Fraud and Risk Detection
~ Delivery logistics
~ Self Driving Cars
~ Robots
Apart from the applications mentioned above, data science is also used in Marketing, Finance, Human Resources, Health Care, Government Policies and every possible industry where data gets generated.
By the end of this course, you will have learnt:
- Anaconda and Jupyter
- Python Data Science tools: NumPy and Pandas
- Data cleaning and preparation
- Data Analysis
- Data Visualisation
- Machine Learning, Big Data and Predictive Analytics
- Data preprocessing and feature engineering with Python
- Supervised learning algorithms with scikit-learn
- Unsupervised learning algorithms with scikit-learn
- Evaluation, model introspection and error analysis
Who should attend
Analysts, Data Scientists, and software developers who want to get a practical introduction to Data Science and Machine Learning with Python.
Prerequisites
Delegates should have attended our intro to Python Programming training course or have equivalent experience – ideally with some exposure to coding with Python.
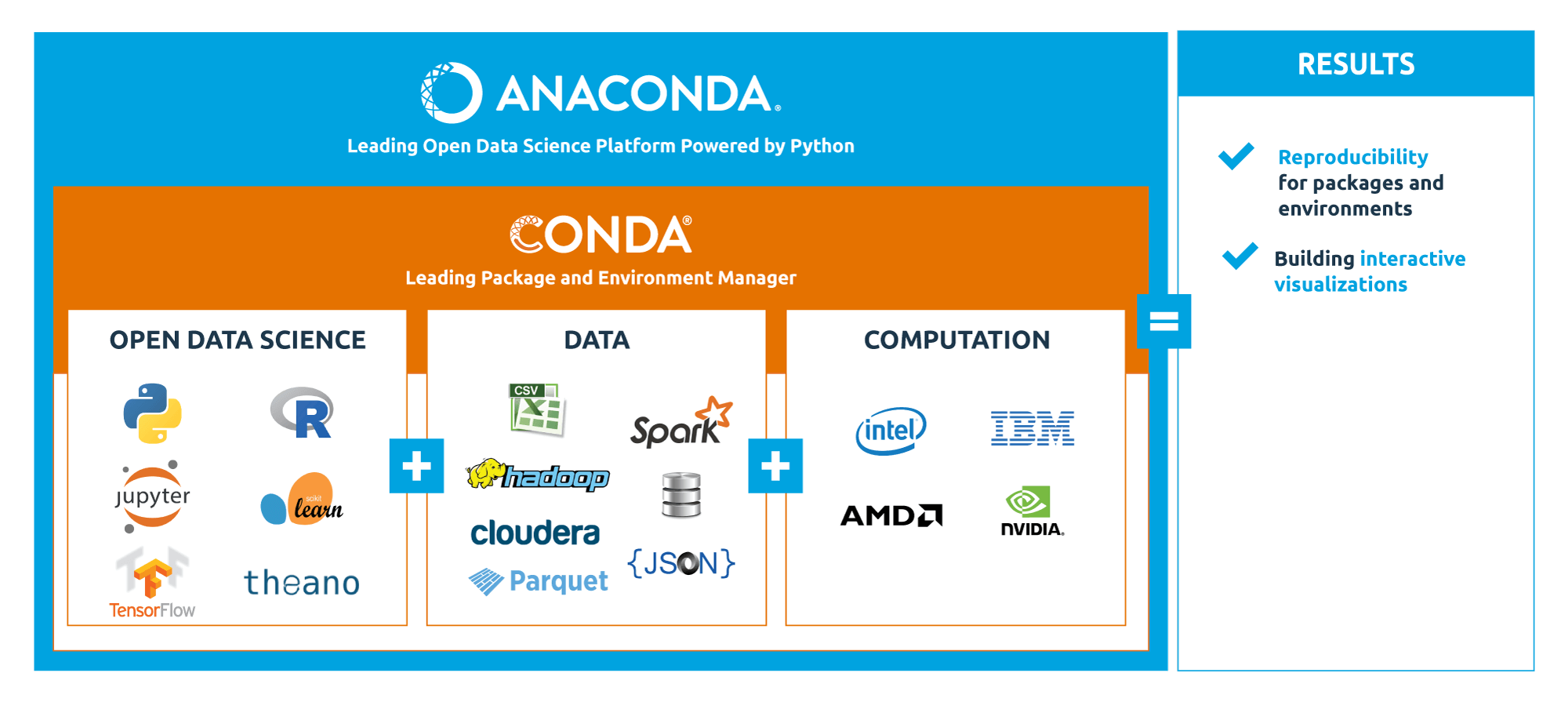
Python Setup (Installation & Packaging)
- Installation, packaging and virtualisation of Python using Conda.
We’ll set up Python using the Anaconda distribution, a free and enterprise-ready Python distribution
that includes hundreds of the most popular Python packages for science, math, engineering and data
analysis. Anaconda comes with Conda, a cross-platform tool for managing packages and virtual
environments. We’ll also set up Jupyter, a web-based interactive environment where users can
organise, write and run their Python code in notebooks.
Python Core Concepts and Best Practices
- Introduction to Python basic concepts, data structures and control flow structures.
Overview of how Python is used for Data Science and Data Analytics projects.
Notions of Object-Oriented Programming and Functional Programming, applied to the design of
Python applications and analysis pipelines using best practices.
Python Data Science Tools
- We’ll explore the most important Python tools for Data Science.
NumPy, short for Numerical Python, is one of the main building blocks for scientific computing in
Python. It provides high speed manipulation of multi-dimensional arrays and it’s used by higherlevel libraries (like pandas) to support sophisticated analytics with high speed computation.
pandas is a highly performant library for data manipulation and data analysis in Python.
It’s built on top of NumPy and optimised for performance, while offering a high-level interface.
We’ll discuss how to create and manipulate Series and DataFrame objects in pandas, accessing data
from multiple sources, cleaning and transforming data sets to get them in the right shape for
advanced analysis.
Accessing and Preparing Data
- Data can come in multiple formats and from multiple sources. We’ll examine how to read and write data from local files in different formats, and how to access data from remote source.
Data cleaning and data preparation are the first steps in a data analysis project, so we’ll discuss how
to perform data transformation to get ready for further analysis.
Data Analysis
With our data in the right shape, we’re ready to analyse them in order to extract useful insights.
We’ll perform the computation of summary information and basic statistics from data sets.
We’ll approach split-apply-combine operations with Data Frames, in order to perform advanced
transformations and reshaping our data with pandas. We’ll query our Data Frames using the
powerful group-by method.
Data Visualisation with Python
- Data analysis benefits from the visualisation of data.
If a picture if worth a thousand words,
complex data structures can be easier to understand and analyse using effective visualisation
techniques. Communicating the results with non-technical users is also a challenge that
visualisation techniques help to overcome.
Machine Learning with Python:
Machine Learning and Predictive Analytics
Machine Learning is a field of computer science that gives computers the ability to learn without being explicitly programmed. Machine Learning algorithms can learn from, and make predictions on data. With the wealth of data available today, companies can take advantage of Machine Learning techniques to gain actionable insights and ultimately improve their business.
Using scikit-learn, the core Machine Learning library for Python, attendees will learn how to implement Machine Learning systems to perform predictions on their data.
Enroll TODAY: Click Here >> Python for Data Analysis Training in Nigeria
Click to start learning while you earn and grow…

Related posts:
 Data Science with Python for Analysis, Machine Learning and SPSS for Research Training
Data Science with Python for Analysis, Machine Learning and SPSS for Research Training
 Pandas Tutorial- How to run analysis using Pandas Python
Pandas Tutorial- How to run analysis using Pandas Python
 Pandas Tutorial- How to run analysis using numeric python (numpy) with example
Pandas Tutorial- How to run analysis using numeric python (numpy) with example
 Data Science and Visualization with R Programming- Abuja Lagos Owerri Nigeria
Data Science and Visualization with R Programming- Abuja Lagos Owerri Nigeria