
- February 8, 2019
- Posted by: SouTech Team
- Category: Data Analysis and Virtualization, Others
Do you know why we need data scientists? its because of the great importance of revealing insightful information about very huge data sets which might not have meaning before its cleaned, visualized and made to really give a descriptive inference of the data. Also data science has its application in many fields like accounting, law, medicine and in many other fields.
Your car insurance costs less if you pay your bill on time. That’s because insurance industry data scientists found that people that pay bills promptly are less likely to be in accidents. How did they even think to ask that question? How did they accumulate the accident data and compare it to the billing information to establish the correlation? What other revelations are buried in those numbers?
Still, it’s not the mysteries they unveil so much as that process itself that defines the field of data science.
According to quite some literature and research there are three aspects to data science which differentiate it from pure statistics:
- Data Collection
- Data Modeling and Analysis
- Problem Solving and Decision Support
But while those three steps provide a high-level overview of what data scientists do on a daily basis, there’s still a lot of mystery when it comes to the details of the process.
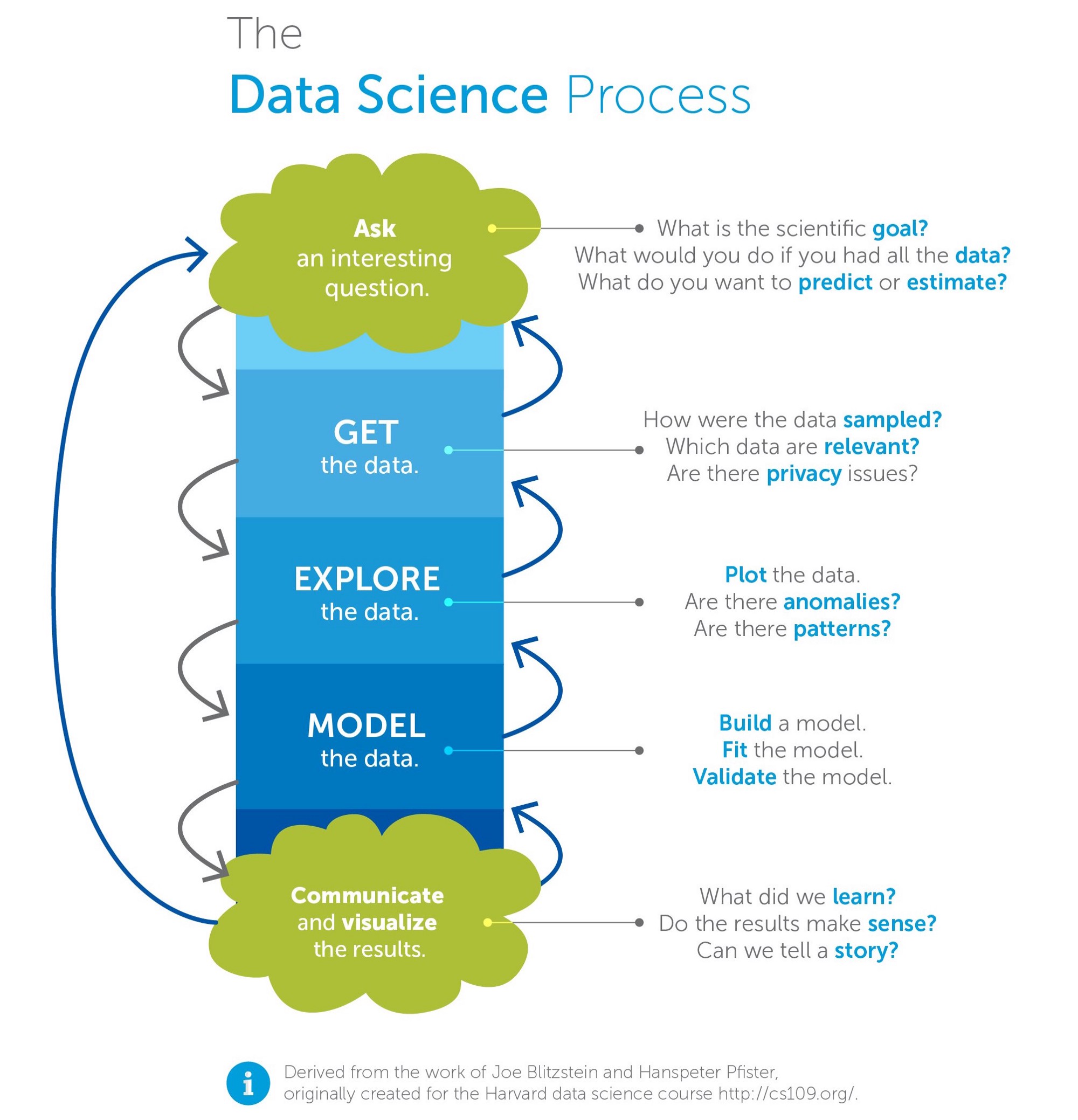
The data science process is a recursive one; arriving at the end will take a good data scientist back to the beginning again to refine each of the steps based on the information they uncovered.
But each round begins with a question.
Step 1. Ask an Interesting Question
Whether it originates in the mind of the investigating data scientist or as a request from other parties, every inquiry starts as a question to be answered.
- Is there a business goal to achieve?
- Some object of scientific interest that would be helpful to discover?
- What parameters would the ideal answer fulfill?
Step 2. Design a Data Collection Program
In many cases, data scientists work with existing data sets collected in the course of other investigations. But the way that data is gathered and stored can limit the questions that may be answered from it and relevant data is not always immediately available.
With the question in mind, the data scientist will decide how to gather the information required to answer it:
- Establish whether or not the data exists in the real world and is relevant to the question
- Devise a collection scheme to acquire it
- Logistical considerations
- Cost?
- Privacy issues?
- Coordinate with departments or agencies needed for collection program liaison
Want to start a career in data science? Click Here >>> Start a Data Science Career in Nigeria
Contact 08034121380 to speak with a course adviser now!
Step 3. Collect and Review the Data
Even the best designed data collection system will result in some quirks and oddities in the data as it actually becomes available– typos, falsification, or frequently misunderstood questions on badly designed forms can all present data sets that are less than factual.
As the data is collected, the data scientist will review it to revisit the collection program and get a feel for the set:
- Store the incoming data in a way that will allow further modeling and reporting
- Join data from multiple sources in a relevant and logical manner
- Check for anomalies or unusual patterns
- Caused by the collection process itself, or do they reflect the topic of investigation?
- Possible to correct, or do they require a new collection scheme?
Step 4. Process the Data
Either due to anomalies found in step 3 or just the general and common necessity of cleaning up messy raw data, the data scientist will have to “wrangle” it before moving further into the modeling process.
Also known as “munging” this hard-to-define step is one of the ways that data scientists make the magic happen—bringing skills and intuition to bear to take messy, incoherent information and shuffle it into clean, accessible sets.
- Decide on the tools to use to comb through the raw data
- Tools: R programming, Python programming , SQL programming
- Devise scripts to correct issues or reformat the data
- Store the munged data as a fresh data set or use programmatic pre-processing for each subsequent query
Step 5. Model and Analyze the Data Sets
With all the important groundwork complete, the data scientist will get down to the fun stuff— diving into a clean data set and applying the pick-and-shovel algorithms that will pluck meaning from it:
- Build a data model to fit the question
- Validate the model against the actual collected data
- Perform the necessary statistical analyses
- Machine-learning or recursive analysis
- Regression testing and other classical statistical analysis techniques
- Compare results against other techniques or sources
Step 6. Visualize and Communicate the Results
The most challenging part of the data scientist’s job is taking the results of the investigation and presenting them to the public or internal consumers of information in a way that makes sense and can be easily communicated:
- Graph or chart the information for presentation
- Interactive, allowing users to explore directly?
- Tools: R, Python, Tableau, Excel
- Tell a story to fit the results
- Interpret the data to describe the real-world sources in a plausible manner
- Assist decision-makers in using the results to drive their decisions
- Answer follow-up questions
- Present the same data in different formats for specific purposes: reports, websites, compliance purposes
The process is rarely linear. Each step can push a data scientist back to previous steps before reaching the end of the process, forcing them to revisit their methods, techniques, or even to reconsider whether or not the original question was the right one in the first place.
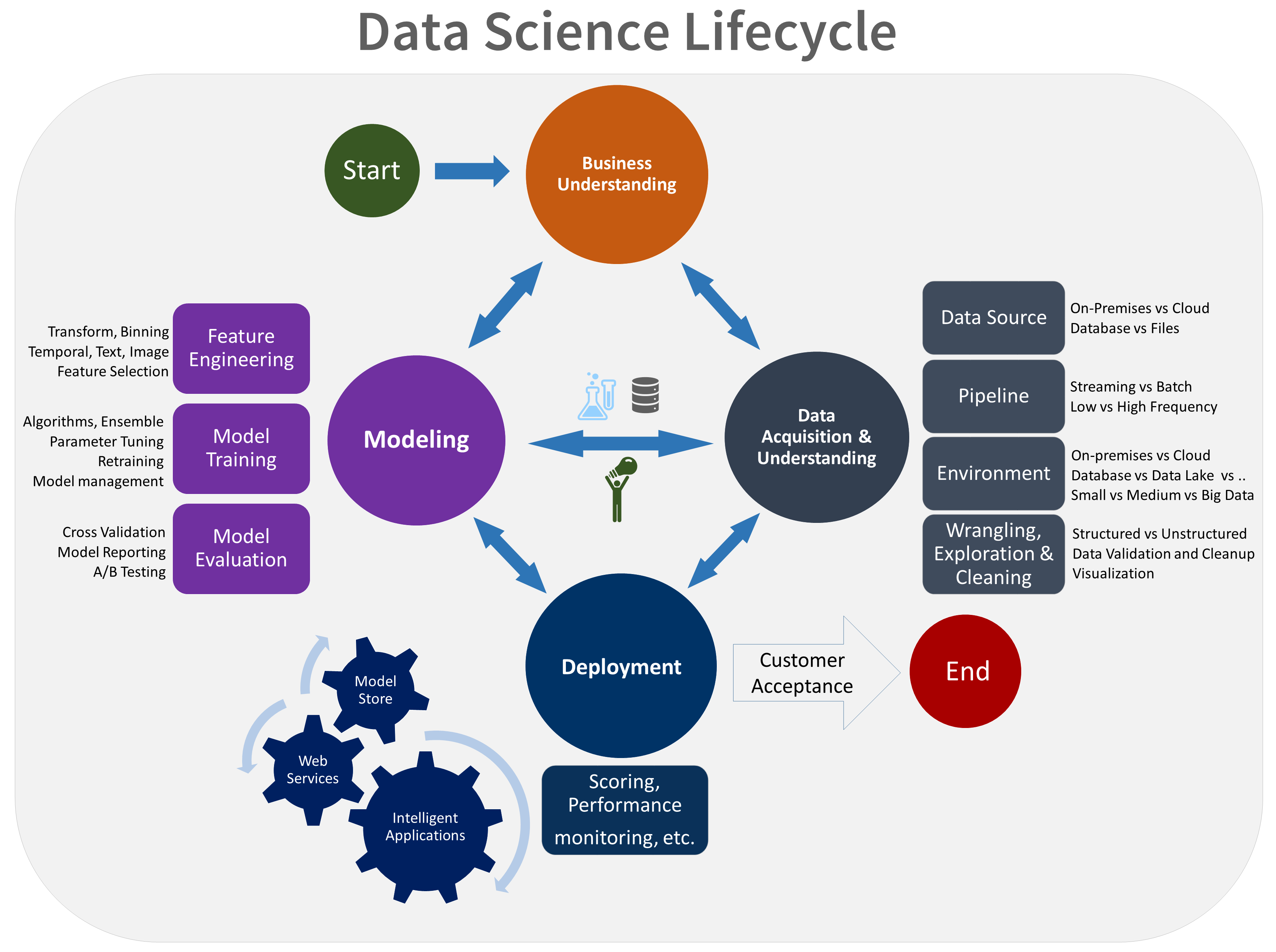
And, having finally come to a definitive result, the data scientist will almost always find that the answer simply sparks more questions: the process begins again!
Want to start a career in data science? Click Here >>> Start a Data Science Career in Nigeria
Contact 08034121380 to speak with a course adviser now!
Related posts:
 Data Science and Visualization with R Programming- Abuja Lagos Owerri Nigeria
Data Science and Visualization with R Programming- Abuja Lagos Owerri Nigeria
 Data Science Tutorial Guide: Nigerian Population Data analysis Case Study
Data Science Tutorial Guide: Nigerian Population Data analysis Case Study
 Python Data Science Tools: How to Install Jupyter NoteBook Tutorial
Python Data Science Tools: How to Install Jupyter NoteBook Tutorial
 Why You Need to Learn IBM SPSS Data Analysis Software Now
Why You Need to Learn IBM SPSS Data Analysis Software Now
 Ethical Hacking , Data Science, Digital Growth Hack Workshop in Owerri- SOUTECH Hub
Ethical Hacking , Data Science, Digital Growth Hack Workshop in Owerri- SOUTECH Hub